
[Editor's Note: Churn is becoming even more difficult to measure these days due to increased privacy around customer transaction data. This article/white paper previously published by Ellipsis explores an alternate approach to measuring churn: Kalman filters. Ellipsis first discovered this approach to customer data science from an academic research paper. Make sure to put on your analytical and thinking cap before you dive into this article!]
SUBSCRIBE TO THE WISE MARKETER NEWSLETTER
Ellipsis is in the customer loyalty business; our focus is on last 2 elements of the Get – Keep – Grow mantra of customer centric organisations.
We do this by applying a data driven approach with our clients. The methods, tools and benchmarks we use we call Customer Science® and it includes models that identify customers that (in their behaviour) appear to be about to leave your business, to cease spending with you, that will ‘churn’.
These models are generically called churn models and traditionally use historical customer behaviour data to detect changes that indicate customers will churn so that offers can be made to re-engage them and keep them loyal.
Customers have a churn propensity added to their profile, to indicate where retention programs should start. Calculating this propensity (popular approaches include logistic regression and classification trees) uses information about the past behaviour of individual customers, and generally, the more data the more accurate the model can be in predicting churn. Model accuracy decreases over time, so they need to be re-run regularly, incorporating most recent customer data.
Not new, the approach is quite successful for many marketing clients who can avoid bothering customers who do not intend to leave and allows those that are ‘wavering’ to receive an offer that may make them stay longer as customers.
But it sits uncomfortably with the current consumer privacy trends that insist companies implement measures for data minimisation (limit the amount & length of time customer data is retained) and data anonymisation (making sure specific individuals cannot be connected to the transactions).
Europe’s GDPR and the California Consumer Privacy Act (CCPA) are reinforcing these requirements with regulation. Browsers are increasingly allowing users to block third party data gathering, quickly relegating the ‘old’ cookie to the internet dustbin. Consumer protection authorities are discouraging merchants from linking & tracking payment card details for individuals, even when they do not present a loyalty card.
The looming challenge is to continue identifying ‘at risk’ customers when you do not have access to a substantial database of past behaviour data.
We have been on the lookout for an answer, and recently found an academic paper that makes us feel positive there is a solution that is promising: “No Future Without the Past? Predicting Churn in the Face of Customer Privacy”.
These researchers applied an analytical technique called Kalman Filters to the churn prediction challenge. These filters are used to predict future states where the predictions and the data inputs have errors. Predicting where aircraft will be, based on various radar readings is a good example of how quickly and accurately these filters can be used.
The process is to initially segment customers (to step away from the need for individual customer tracking), then apply Kalman Filters to arrive at an initial estimate of churn propensity. All subsequent data inputs refine the estimate in an iterative process that decreases uncertainty over time, even if the measurements/data are uncertain. So for each cohort of customers you can estimate their likelihood to churn and take appropriate marketing action, or not.
The key point is that once the initial iterations of the filters are applied to the customer data, it is no longer required. Subsequent observations will reduce model errors further as they continually ‘self-tune’. Holtrop et al; “…its recursive nature requires only knowledge of past model parameters to generate churn predictions.” You can safely remove the old customer transactions without compromising the accuracy or reliability of the model.
For those who are intrigued but not mathematicians, Kalman Filters iteratively…
- Calculate the ‘Kalman Gain’ – the weighing of errors in the initial /previous estimate and actual measurement to produce a modifier that is applied to…
- The previous estimate, making it a more accurate prediction of the Actual Measure, and
- Calculate the error in the previous estimate as input into the ‘Kalman Gain’ next time around with new data inputs
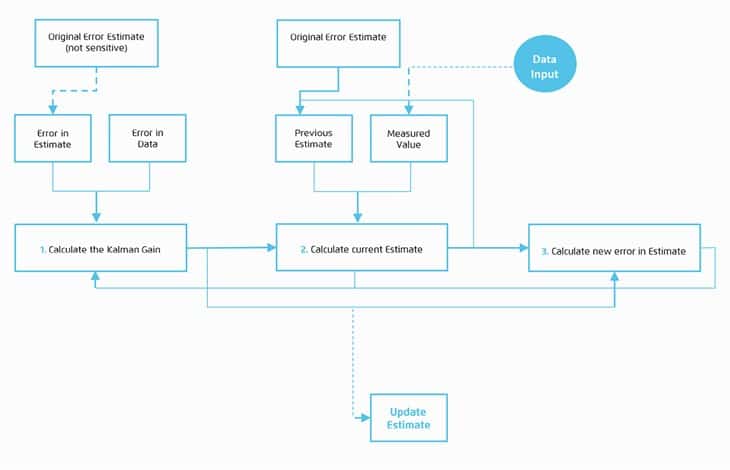
This may not be the best modelling strategy for every customer centric organisation, but the published studies, using Telco and Insurance data confirm it can be effective for some.
The important message is that there are promising approaches that will allow you to continue applying Customer Science® to customer loyalty challenges — while complying with the imperatives to observe data minimisation and data anonymisation.
As marketers adapt to the changing requirements of our customers, balanced with the need to make our communications hyper-relevant, innovation will also be required by analytics teams. We will continue to look for innovative ways to engage and retain customers, and we would love to discuss any new approaches that you have implemented or encountered.
Ellipsis specialise in Loyalty and Customer Insights. We help our clients become customer centric, because we believe getting this right is crucial to creating value.
Please get in touch, we’d love to talk.